will stedden
will steddenAnalyzing Edge.org forum data - Experiences with Crowdsourcing Analysis
Epistemic status: First foray into this type of analysis, expecting a 33% chance of at least 1 major technical error.
I recently signed up to take part in an experiment on crowdsourcing data analysis run by Martin Schweinsberg out of ESMT Berlin. For this project, a bunch of analysts are going to try to determine independently whether a hypothesis is true using the same data set. Then we'll get back together at the end to see how variable our conclusions were. What we really hope to get out of this is some understanding of whether independent analysts can produce reliable reproducible results or if the many different ways of analyzing any complex data source will inevitably lead to discrepancies in interpretation.
I'm very interested to be part of this study to promote reproducible and open scientific practices. After seeing the preprint of the previous round of crowdsourced analysis and Martin's crowdsourcing science course, I feel like this will be an interesting experience. I'm hoping to learn a lot about social science research and statistical inference techniques.
I'll be writing more about the collaboration experience in a followup post once I get feedback on my contribution, but here, I wanted to write up my initial analysis of the data. I should point out that I'm not that experienced with social science research so this just a novice's attempt at using some statistical methods. Hopefully, it doesn't turn out that I've made too many mistakes.
The Edge.org Data Set

For this study we are going to be trying to answer a few questions about how scientists and technologists communicate. To do this we're going to be looking at communications from an online forum dedicated to scientific discussions called The Edge. I had never heard of it but from what I can gather, Edge.org is designed facilitate important intellectual discussion about the "edge" of what science has concluded about reality.
To arrive at the edge of the world's knowledge, seek out the most complex and sophisticated minds, put them in a room together, and have them ask each other the questions they are asking themselves.
Importantly, the forum isn't open to anyone and the contributors are selected by Edge based on their creative work. These contributors include Daniel Kahneman, Marissa Meyer, Craig Venter, and many other academics as well as writers, entrepreneurs, business leaders, and more. These individuals are supposed to make up a class called the third culture, which I think is in contrast to the two culture mentality of science vs. "literary intellectuals." This is how the website describes the third culture:
The third culture consists of those scientists and other thinkers in the empirical world who, through their work and expository writing, are taking the place of the traditional intellectual in rendering visible the deeper meanings of our lives, redefining who and what we are.
To read more about the background on The Edge, you can read this historical account by the creator. But perhaps the easiest way to get acquainted (and the way I first approached it) was to look at a few sample threads.
Example forum thread
As a quick example of what conversational threads really end up looking like, I randomly selected a post titled Mirror neurons and imitation learning as the driving force behind the great leap forward in human evolution
From the few other examples I looked up, I get the sense that, most of the time, the conversation looks kind of like one person going on a rant about their personal project or promoting a book, and then a bunch of academics debating at length who really deserved credit for that idea.
While Edge and the third culture ideal is a cool idea, people are people I guess. Fortunately, the content being stuffy academic jibber-jabber makes it easier to analyze the data without getting caught wasting time reading the articles.
The Edge.org community
The data table provided for the analysis consists of about 7975 comments provided by 728 users across 522 threads. About half of these threads are actually live recorded discussions, but I removed those to focus down on just online discussion in 3657 comments from 681 users across 344 threads. Some threads were more popular than others, and some users were more prolific than others. To get a sense of the data and the structure of the community generating the data, I started with some basic preliminary plots.
One cool thing about the data set is that they have categorized all the community members based on their job title and academic discipline (if they are academics). This gives a pretty clear insight into what kinds of people are making contributions. There are actually a lot of people with non-academic jobs on the forum, though professors do make up the bulk of the population. For those who have a discipline, there seems to be an overabundance of those who focus on social sciences. Of course, I'm not sure if that is due to there actually being more social scientists in the world or if they just are more drawn to this forum, though I suspect the latter.

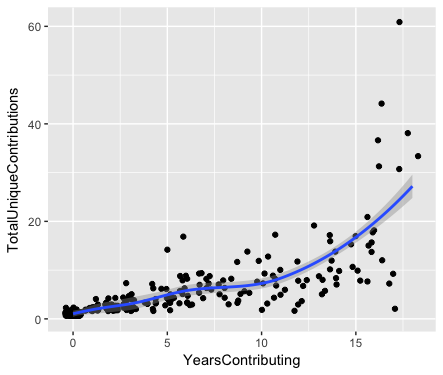
Next, to get a sense of engagement, I plotted the number of contributions coming from each community member as a function of how many years they had been active in the community. The result showed that there were a few members who had been contributing since the forum began, and those few individuals were very active. However, the vast majority of users only made a small number of contributions during 1 year.
Finally, this last set of figures shows that certain threads were more popular than others, and that the number of threads created has varied by quite a bit over the years.

Fortunately, the forum data hasn't offered too many surprises up to now. So I feel a little more comfortable using it to address the hypotheses that I've been tasked with investigating.
Testing hypotheses
The aim of this project is to test two hypotheses provided by the project organizers.
- A woman’s tendency to participate actively in the conversation correlates positively with the number of females in the discussion.
- Higher status participants are more verbose than are lower status participants.
By the end, I know I'm supposed to provide some type of effect size to display the significance of any finding. I normally don't work in the language of formal effect sizes (folks at the company I work for glaze over when I toss around p-values) so I'm going to try to keep my analysis simple. Hopefully if I just follow the basic guidelines on linear models, I can justify my usage to any reviewers.
I'm personally much more interested about the question of female participation in science. From personal experience, I've noticed differences in communication styles between men and women and I thought it would be interesting to see if there were signals of those differences in the online forum data. At the same time I also like the idea of comparing the verbosity of academics, particularly comparing how verbose individuals from different disciplines and job descriptions might be.
In the following two sections, I'll go through my analysis of each hypothesis separately.
Contributions from Women
I find that a lot of the nuance of which direction I'm going to pursue comes down to how I'm interpreting the hypothesis.
A woman’s tendency to participate actively in the conversation correlates positively with the number of females in the discussion.
To flesh out the first hypothesis, I needed to specify what participation means. I'm going to interpret the hypothesis as valid if I can detect whether a woman joining in on a conversation depends on how many other women are in the conversation.
Female contributions across threads
To begin, I wanted to test the simplest evidence that would point to the hypothesis being true. Can I detect whether women self-segregate into certain threads? In other words, are there some threads with a lot more women than we would guess.
The easiest way to see this would be to just visually check if there are lots of crazy outlier threads in terms of female contribution. We can plot the fraction of women in each thread along with a confidence interval to see if there. I used a Wilson confidence interval to determine the significance of the discrepancy from the expected proportion given the sample size in each thread. Because the confidence intervals on very small samples are too large to be meaningful, I've filtered out the threads that have fewer than 5 people.

It looks like there are basically only 3 threads that don't overlap with the expected proportion (solid lines). So at the simplest level, it seems that women are participating in all threads about as much as we would expect.
We can also perform a statistical test of the female proportion of contributors in each thread using a chi squared test of homogeneity. This can be performed easily with R's prop.test function. The results of my prop test (below) show that the differences between female proportion are not significant enough to conclude that women are segregating into groups and only talking with one another. The p-value on the prop test was 0.12, which is widely accepted as not significant.
prop.test(thread_info$UniqueFemaleContributors,thread_info$UniqueContributors)
93-sample test for equality of proportions without
continuity correction
X-squared = 107.96, df = 92, p-value = 0.1224
At this point, I'm thinking that I would feel pretty comfortable concluding that female participation is largely unbiased across threads. However, this is a rich data set so I wanted to continue with some more exploratory analysis.
Digging deeper: female demographics by discipline and job, effects of time, and total contributions
There is some concern that different covariates could influence the rates of female participation. Particularly, I was interested in the gender skew among different disciplines and jobs. Plotting the community size as well as the female makeup of each community showed that female job titles and disciplines were not evenly distributed.
")
The result is largely what you'd expect. Natural science and math is underrepresented in their share of women compared to humanities and social sciences. And the more prestigious professions also show a lower proportion of women. However, the effects are not as severe as you might think. The groups all mostly overlap, but you can tell that there are trends that would probably shake out if we had more participants.
A much bigger issue is that female participation hasn't been constant over time. In fact, the outlying threads from the previous analysis were all from 2010 onward. Obviously, that will be a potential confounding variable in the analysis. As you can see from the following figure, the fraction of contributions from women grew considerably over the past 20 years.
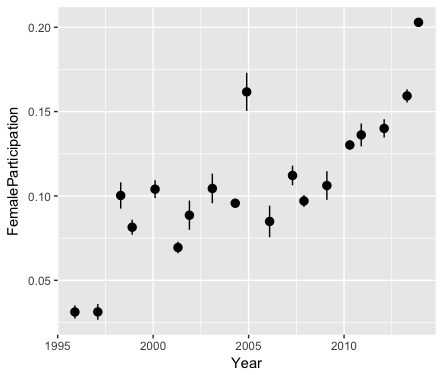
Related to this, there is also one other interesting quirk in the number of contributions made by individuals relative to how long they have been in the community. This last plot basically shows that for recent users the number of contributions made by men and women is approximately the same. However, for users who have been involved for more than 10 years or so, the men seem to have been much more active.
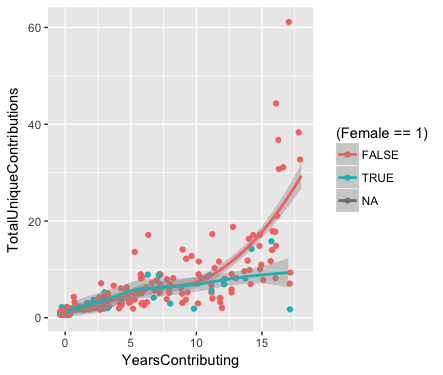
This shouldn't really affect our results, but it's interesting, and it might be useful to keep it in mind.
Taking all of this into account, I wanted to attempt a slightly more sophisticated methodology for modeling female participation.
Predicting the gender of the next contributor
As a final test, I wanted to see whether there was any information about a thread that could be used to predict whether the next person to enter the thread would be a woman. My reasoning behind this was that any variable that would be shown to significantly affect the prediction would meet some definition of significance. Therefore, if the fraction of women participating was predictive, we could conclude that women must be using that information to influence whether they enter the conversation. I believe this is generally how people do statistical inference from linear models, but I could be wrong. In the past, I've mostly always used fitting techniques like this to infer error estimates on parameter values (I used to be a physicist after all).
The way I will operationalize this is to try to predict the gender of each new contributor to a thread given the information about the thread up to the point before this contributor joined. I chose this metric specifically because I didn't want to include any influence from that participant having already joined in the conversation. Therefore, what I'm looking at is the probability that given a new person enters the conversation, what is the probability that that participant is a female.
The main variable I want to test to see if it affects this probability is the fraction of previous contributions in a thread that came from women. To test this variable I had to construct it by using a running sum of the number of unique participants and thread responses from both men and women.
In addition to this primary metric of interest, I also wanted to include a few covariates that I thought might be of interest. In particular, I wanted to see if the thread year, and the overall thread progress (i.e. what fraction of the total length of the thread has already occurred before the participant under question joins the converstaion.)
Without controlling for thread year, I found a very slight effect of the cumulative fraction of comments that came from women.
Additionally, I also found an effect from the thread progress. Women seemed to be less inclined to enter a conversation as it was nearing it's end.
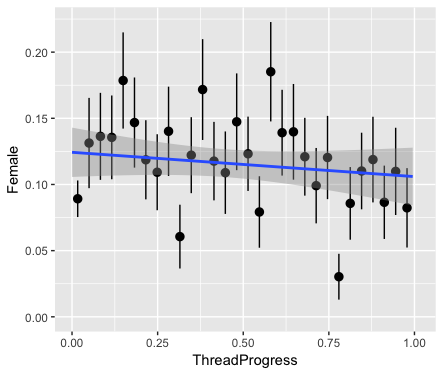
I used the R glm function to infer the significance of the two contributions. The code below produces a summary of the model, with the estimated coefficients and the their test statistic (see wikipedia for more details on the Wald test).
> model = glm(Female ~ OtherFemale_CumFrac + ThreadProgress, family = 'binomial', data_th1 )
> summary(model)
Call:
glm(formula = Female ~ OtherFemale_CumFrac + ThreadProgress,
family = "binomial", data = data_th1)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.9450 0.1233 -15.774 < 2e-16 ***
OtherFemale_CumFrac 1.4296 0.4605 3.104 0.00191 **
ThreadProgress -0.4739 0.1946 -2.436 0.01485 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
In the last column, Pr(>|z|), a p-value is computed for that variable given all the information from the rest of the model. Thus both ThreadProgress and OtherFemale_CumFrac show some correlation with the outcome in question even when taking the other variable into account. From this we could conclude that there is some significant correlation between women joining the conversation and the percent of comments thus far that came from women.
I submitted the above result because I was in a rush to meet the deadline, BUT the story isn't quite over. Long story short, I missed a BIG issue that basically invalidated my result!
OOPS! Adding Thread Year as a Covariate
I mentioned in my analysis abover that female participation varied with thread year. Unfortunately, I forgot to include that as a covariate when performing the regression above. When taking year into account, the significance of the above result evaporated.
Basically, all I had to do to fix the problem was add thread year back into the equation for the glm. Had I done that in the beginning I would have found the following result.
> model = glm(Female ~ OtherFemale_CumFrac + ThreadProgress + Year, family = 'binomial', data_th1 )
> summary(model)
Call:
glm(formula = Female ~ OtherFemale_CumFrac + ThreadProgress +
Year, family = "binomial", data = data_th1)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -101.33251 23.40287 -4.330 0.0000149 ***
OtherFemale_CumFrac 0.60656 0.52847 1.148 0.2511
ThreadProgress -0.49821 0.19466 -2.559 0.0105 *
Year 0.04958 0.01167 4.248 0.0000216 ***
From the last column, Pr(>|z|), we can see the significance p-value is well below 0.05 for the Year variable, whereas the OtherFemale_CumFrac variable is now at 0.25 and thus not significant. Therefore, I have to reject the hypothesis that female participation has been influenced by anything other than time at this point.
Takeaway: no evidence for the hypothesis
Although, I did find a slight effect, the confounding variable of thread year appears to be the real predictor. Therefore, we should accept the null hypothesis that women's participation is not influenced by the participation of other women.
Unfortunately, I didn't double check my work until I started writing this blog post! That means the answer I submitted has a MUCH higher significance that I really found. Oh well, I suppose these are the growing pains of trying to learn how to use an online collaborative data analysis framework. At least I learned, that I need to write up my analysis BEFORE I submit it to make sure my thinking is clear.
Verbose Academics?
There was a second hypothesis to be tested as part of this project.
Higher status participants are more verbose than are lower status participants.
I was significantly less interested in this question so I won't speak to as much detail on this problem as I did above. But there were some interesting points which I'll highlight quickly.
What specifically should we test
This problem is kind of hard because there are lots of reasonable ways to operationalize "verbosity," and answering this hypothesis really requires picking a definition. I actually tested three related measurements before getting to one that had a very weak observable effect. The forum post data included precomputed text analysis of the LIWC metrics. These metrics basically try to boil down complex properties of text into simpler metric(see this manual for lots of details). I just used three simple metrics that I thought would be good measures of verbosity:
- total word count per post (WC),
- word count per sentence (WPS),
- and the LIWC metric for usage of words that are six letters or longer (Sixltr).
For the dependent variable I tried a couple of metrics all of which related to the total citations of the user up to the point of their last contribution on the forum. They all showed basically the same thing so, in the interest of brevity, I'll just report results in terms of the total number of citations. Basically my less ambiguous hypothesis ended up being:
Does a users word usage relate to the number of citations they've had?
I figured the main confounding variables for this study would be the discipline and job title of the contributor so I decided to do a little exploration to see how those related.
How discipline and job affected verbosity
This was one of the things I wanted to know the most. After having lived with three anthropologists for about 6 months, I had a pretty solid preconceived notion about how verbose people in the humanities were. Just plotting the WPS and Sixltr metrics showed that there was some pretty noticeable discrepancies between the disciplines, with social science and humanities coming in at the high end for word length, and social science and natural science coming in at the high end for the Sixltr score.
")
Likewise, when looking at the effect of job title on word count (WC), it seemed pretty clear that the academic job titles were more inclined to writing longer posts.

Clearly, with the large, significant effects that these variable imparted, I figured it might be hard to pick up much signal from the impact of citations.
Impact of citations on verbosity
Interestingly, any effect of citations on verbosity seemed to be at best discipline and job specific. As an example, we can look at the effect of citations on a user's mean Sixltr score, while comparing only members of the same discipline. In the following figure, I group and color users by discipline so that you can follow a colored line to see what the average effect citations had on the Sixltr score.

As you can see most of the disciplines actually have a negative correlation between citations and number of six letter words used. However, the natural sciences seems to show a positive correlation. Likewise, we can look at the same measurement while comparing among members of the same academic hierarchy (1 being assistant professor and 6 being chaired professor).

Again, the results are all over the place, with higher academic rank showing a positive correlation while a lower academic rank has a negative correlation. However, the folks with a low academic rank and few citations appear to be just as verbose as those with a high academic rank and many citations. It almost looks like there is a valley of verbosity among the middle of the pack.
To make a long story short, this is the kind of data where you can slice any story out of it that you want. I chose to keep my tests simple and linear so I had a pretty good feeling that I wasn't going to find any strong effect in this data set.
Results of the modeling
Finally, I tested the hypothesis using the same glm formula as before, though this time I was predicting a gaussian variable rather than a binomial. It turned out that WC and WPS had almost no effect so I will just show the results for Sixltr since that was more interesting.
Call:
glm(formula = Sixltr ~ Total_Citations, family = "gaussian",
data = user_wc)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 28.492929260 0.510552842 55.808 <2e-16 ***
Total_Citations -0.000008705 0.000014841 -0.587 0.559
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Again, if we analyze the printout, we can see that the p-value for Total_Citations is well above the minimum for significance of 0.05. Thus we would reject that Total_Citations has much of an impact on Sixltr. I repeated this modeling exercise for a bunch of different citation related variables and seeing if they had an impact on WC, WPS and Sixltr. None of them showed significant results. I also tried a few second order models, where I looked at whether citations could have a different impact given combinations of other variables (e.g. did citations matter if we controlled for tenured professors in the social sciences). I started to see a few significant results (p < 0.05), but by that time I had been testing so many hypotheses that I was going to need some serious effect sizes to believe anything.
Takeaway: basically no evidence for the hypothesis.
I had to conclude that citations as a measure of academic status wouldn't map directly to usage of six letter words. But at this point in the project, I was running low on time, and every code rerun correlated with me uttering four letter word. Eventually, I had to give up even though I wasn't totally satisfied with my results.
As usual, all my code is on the lots-of-things Github for you to tear into should you so desire. Best of luck, and hope you can get further on it than I did.
* A note on dataexplained.org
As part of this project, we were initially supposed to do all of our analysis using the website dataexplained.org. This site had an RStudio console that recorded every line of code that was executed. Based on the video instructions, the analysts were then supposed to group their code into logical blocks and document why they chose that line of reasoning. Initially, I thought this was an awesome idea, and I was excited to try to use it to record and document my analysis process. Unfortunately, the website was poorly designed and I quickly started to experience performance problems that made it impossible to use it. The IT team eventually fixed the issues but by then I had already started doing a fair bit of work locally. I manually reproduced the majority of the work in the interface, but I'm disappointed that the interface wasn't really built well enough to make it useful. In particular a lot of the questions they ask are poorly worded, which just leads skipping the question. Hopefully in future rounds, there will be a better method to record every step of the process.